
Description-aware Fashion Image Inpainting with Convolutional Neural Networks in Coarse-to-Fine Manner
F. Kınlı, B. Özcan, F. Kıraç
6th International Conference on Computer and Technology Applications (ICCTA 2020, former ICCIT)
Abstract
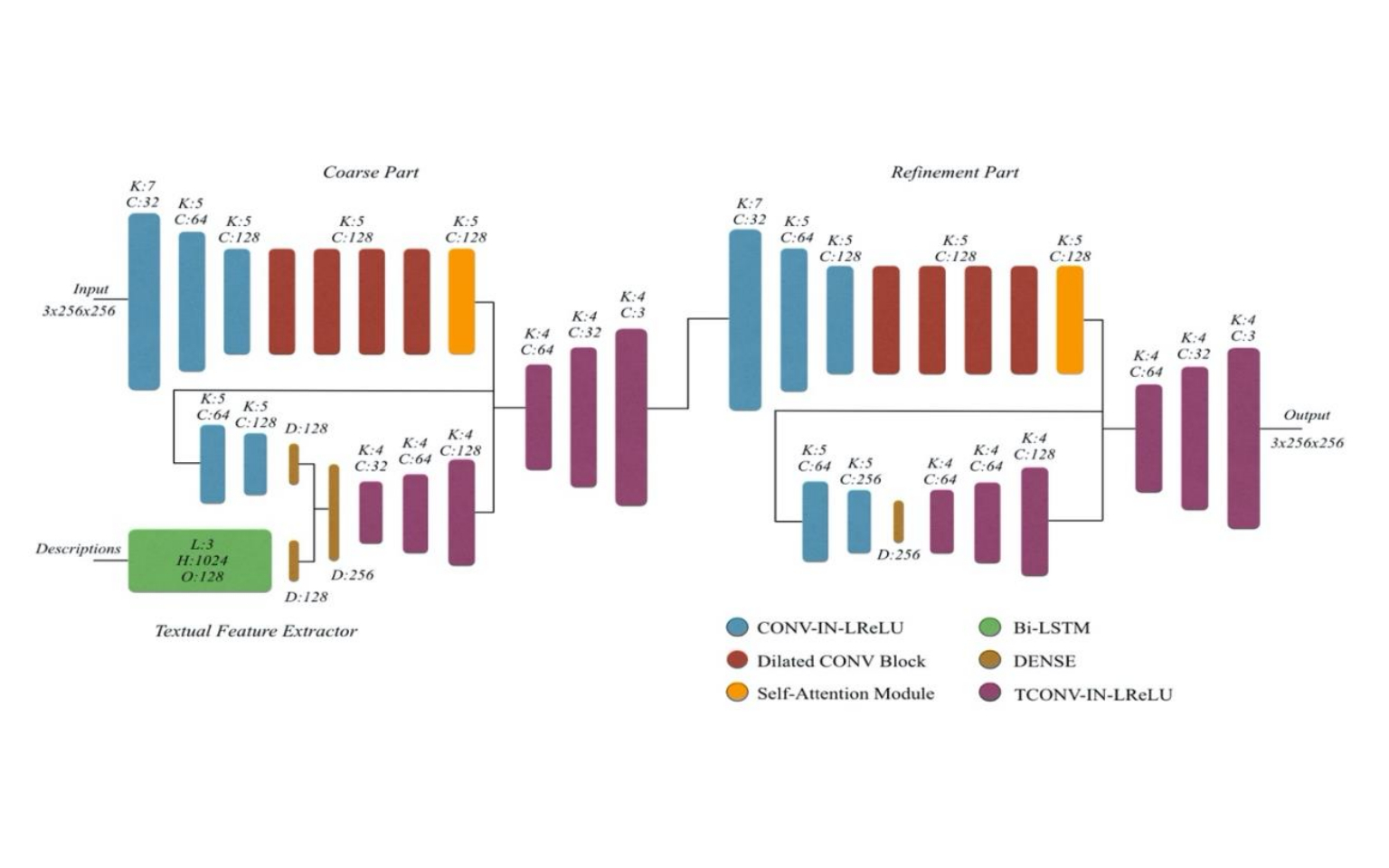
Inpainting a particular missing region in an image is a challenging vision task, and promising improvements on this task have been achieved with the help of the recent developments in vision-related deep learning studies. Although it may have a direct impact on the decisions of AI-based fashion analysis systems, a limited number of studies for image inpainting have been done in fashion domain, so far. In this study, we propose a multi-modal generative deep learning approach for filling the missing parts in fashion images by constraining visual features with textual features extracted from image descriptions. Our model is composed of four main blocks which can be introduced as textual feature extractor, coarse image generator guided by textual features, fine image generator enhancing the coarse output, and lastly global and local discriminators improving refined outputs. Several experiments conducted on FashionGen dataset with different combination of neural network components show that our multi-modal approach is able to generate visually plausible patches to fill the missing parts in the images.
Bibtex:
@inproceedings{kinli2020description,
title={Description-aware fashion image inpainting with convolutional neural networks in coarse-to-fine manner},
author={K{\i}nl{\i}, Furkan and {\"O}zcan, Bar{\i}{\c{s}} and K{\i}ra{\c{c}}, Furkan},
booktitle={Proceedings of the 2020 6th International Conference on Computer and Technology Applications},
pages={74--79},
year={2020}
}